방학동안 학회에서 김성훈 교수님의 PyTorch Zero To All 강의로 공부를 하게 된 김에 스스로 정리해보려고 합니다.
좋은 강의 공유해주신 김성훈 교수님께 감사드립니다.
강의링크:
https://www.youtube.com/playlist?list=PLlMkM4tgfjnJ3I-dbhO9JTw7gNty6o_2m
PyTorchZeroToAll (in English)
Basic ML/DL lectures using PyTorch in English.
www.youtube.com
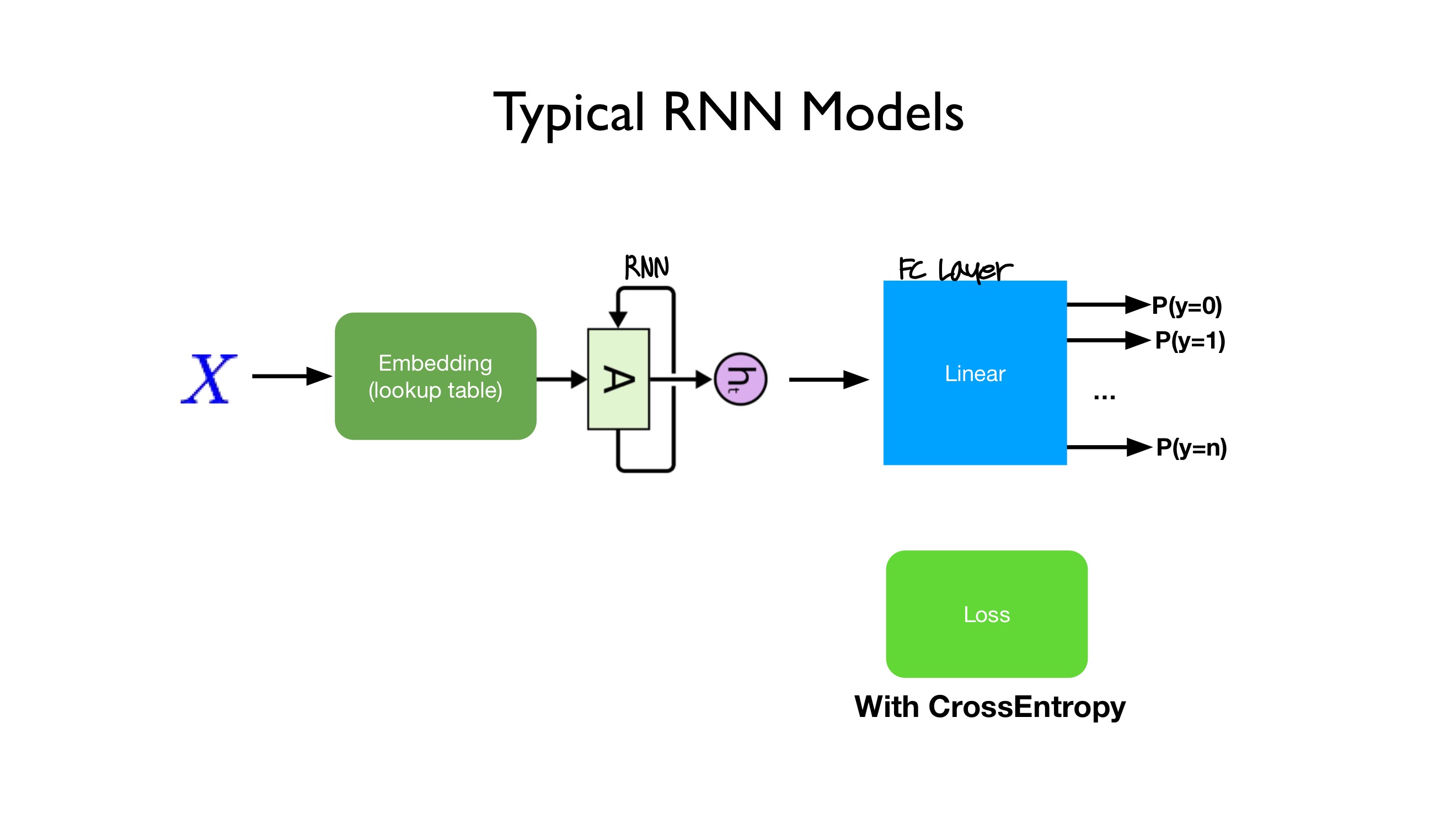
일반적인 RNN 모델은 아래와 같은 구조를 지닙니다. Input X가 Embedding Layer(수치화되어 있지 않은 자연어를 수치화, 벡터화 해주는 Layer)를 거친 후 RNN의 input으로 들어가게 되고, 그로 인해 출력된 output이 fully connected layer를 거쳐, 특정한 값으로 출력됩니다. 이 값과 CrossEntorpy와 같은 특정한 Loss metric을 이용해 loss를 계산하고 training이 이루어지게 됩니다.
이번 강의에서 중점적으로 다룰 RNN을 이용한 task는 RNN Classification입니다.
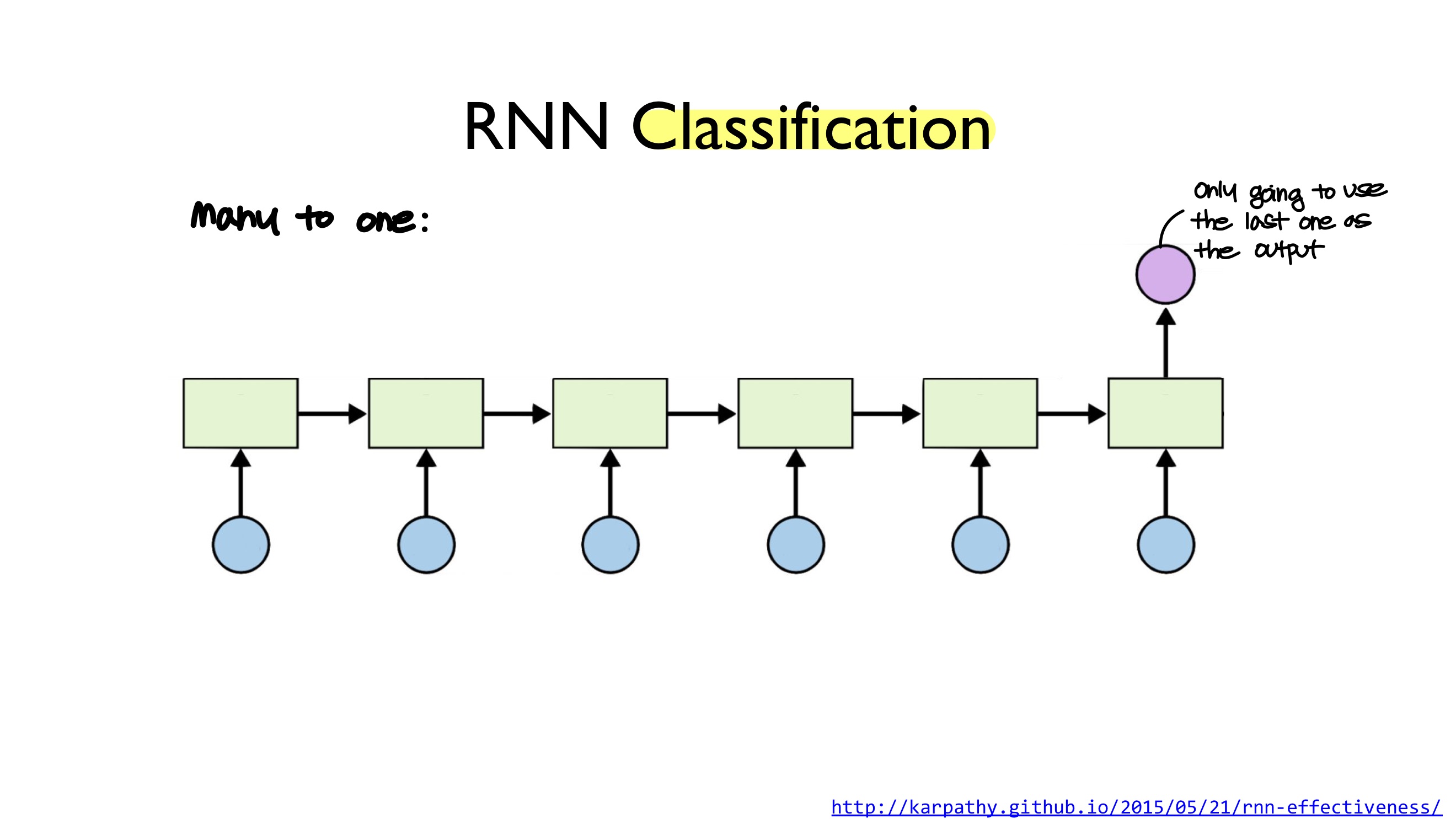
RNN Classification에서는 지난 시간에 다루었던 다양한 구조들 중 many to one 구조를 사용합니다.
따라서 sequence of inputs를 사용하지만, output으로는 마지막 layer에서 출력된 것 하나만을 사용합니다.
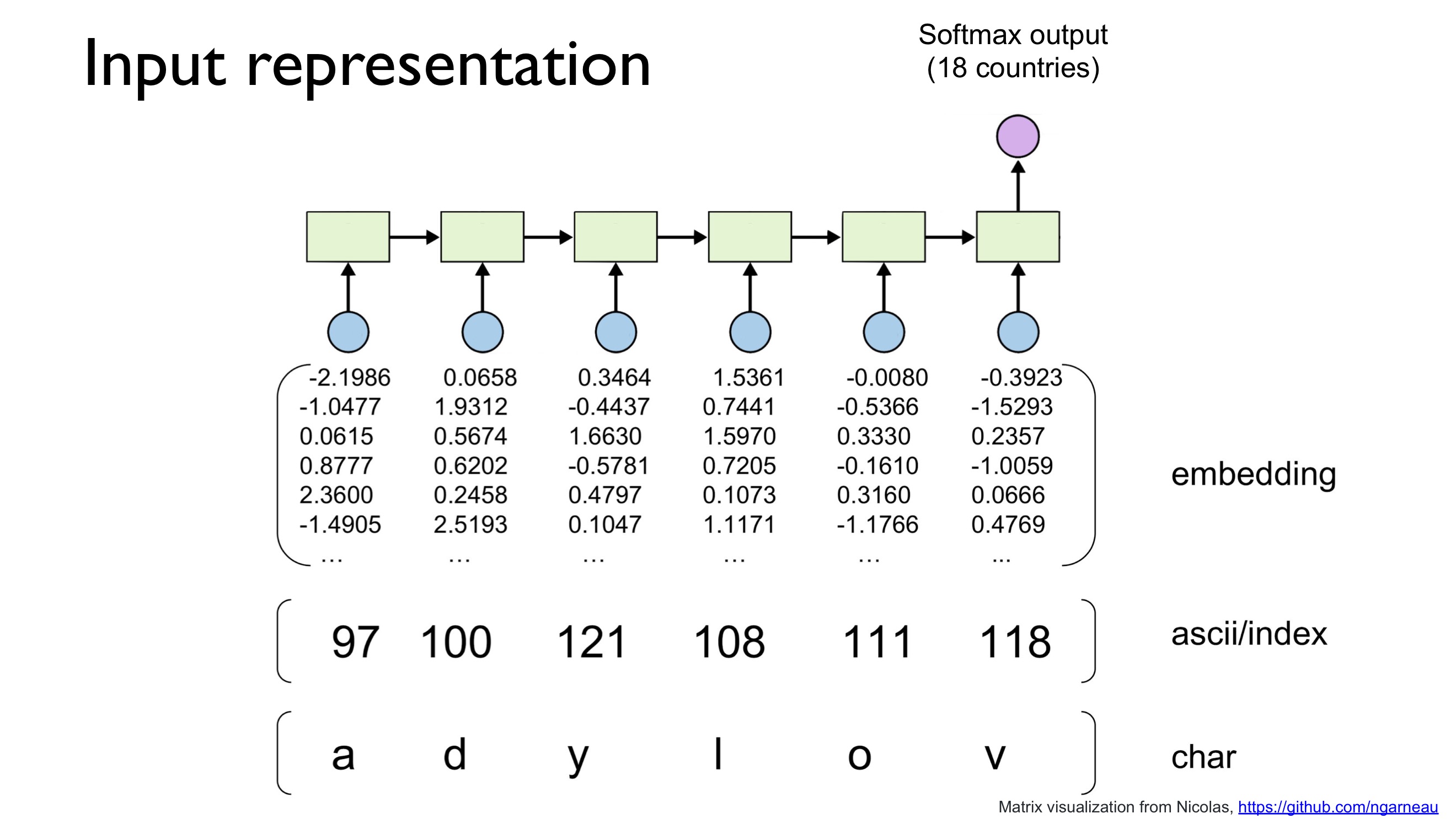
강의에서 사용하는 예제는 name classification으로, 이름을 보고 나라를 맞추는 task를 수행합니다.
Input으로는 이름을, character로 분리하여, 각 cell에 하나의 char 씩 입력합니다. Output으로는, 총 18개의 나라가 있기 때문에, 18개의 값을 갖는 Softmax Output이 사용됩니다.

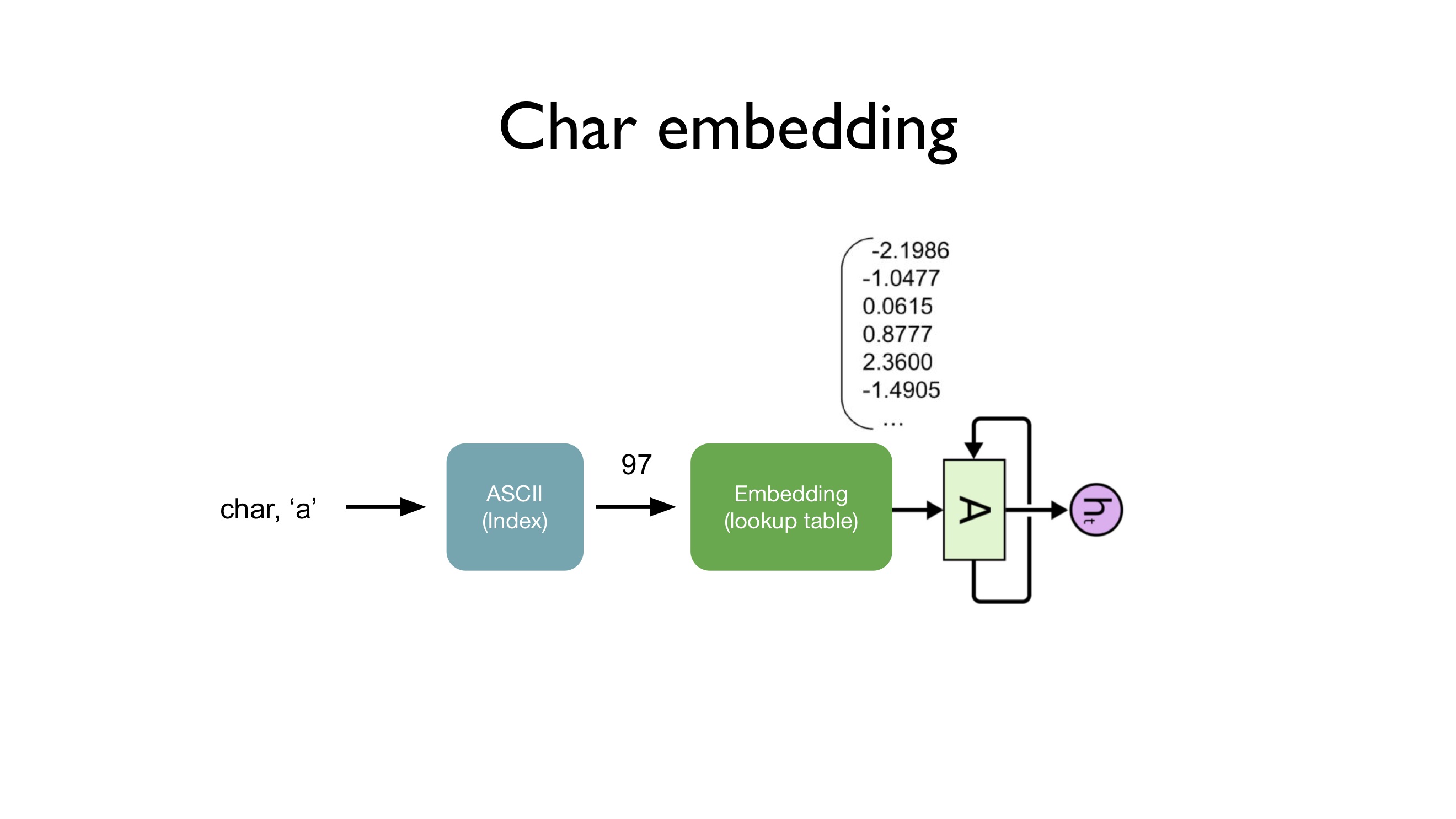
보통 unique한 character를 찾아, vocabulary를 만들어, vocabulary ID를 embedding layer의 input으로 사용하지만, 이 경우에는 알파벳이라는 것을 알고 있기 때문에 편의상 ASCII code로 변환한 후 embedding layer에 입력해주었다고 합니다.
# Original code is from https://github.com/spro/practical-pytorch
import time
import math
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
# Parameters and DataLoaders
HIDDEN_SIZE = 100 # rnn_input_size
N_CHARS = 128 # ASCII code에 총 128 종류가 있기 때문에
N_CLASSES = 18 # 분류하고자 하는 나라가 18 나라이기 때문에
class RNNClassifier(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers # single layer
self.embedding = nn.Embedding(input_size, hidden_size)
# embedding layer의 output이 rnn의 input으로 들어가기 때문에 output size를
# rnn의 input size와 맞춰주어야함
self.gru = nn.GRU(hidden_size, hidden_size, n_layers)
# GRU(Gated Recurrent Unit) 사용
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input):
# Note: we run this all at once (over the whole input sequence)
# input = B x S . size(0) = B
batch_size = input.size(0)
# 이 input은 ASCII array이기 때문에 batch_size x sequence length의 size를 지님
# input: B x S -- (transpose) --> S x B
input = input.t()
# 위의 GRU를 정의할 때, batch_first option을 사용하지 않았기 때문에
# rnn의 input은 seqence_length x batch_size x input_size(여기서는 hidden_size) shape이어야 함
# Embedding S x B -> S x B x I (embedding size)
print(" input", input.size())
embedded = self.embedding(input)
print(" embedding", embedded.size())
# Make a hidden
hidden = self._init_hidden(batch_size)
# 첫 hidden layer에 feed할 hidden state initialize
output, hidden = self.gru(embedded, hidden)
# 이 output은 우리가 사용하고자 하는 last output만이 아니라 각 layer에서의 모든
# output을 다 담고 있음
# hidden에는 final hidden state for the input sequence가 할당됨
print(" gru hidden output", hidden.size())
# Use the last layer output as FC's input
# No need to unpack, since we are going to use hidden
fc_output = self.fc(hidden)
# 마지막 hidden state와 마지막에 Output layer에 전달되는 값은 동일하기 때문에
# fully connected layer에 hidden을 전달함
print(" fc output", fc_output.size())
return fc_output
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers, batch_size, self.hidden_size)
return Variable(hidden)
# hidden state initialize
# Help functions
def str2ascii_arr(msg):
arr = [ord(c) for c in msg] # ord() function returns the ASCII code of the given input
return arr, len(arr)
# pad sequences and sort the tensor
def pad_sequences(vectorized_seqs, seq_lengths):
seq_tensor = torch.zeros((len(vectorized_seqs), seq_lengths.max())).long()
# len(vectorized_seqs) x seg_lengths.max() 크기의 zero tensor 생성
for idx, (seq, seq_len) in enumerate(zip(vectorized_seqs, seq_lengths)):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# 각 seq의 length가 유효한데까지는 원래의 seq로 채우고 그렇지 않은 경우 0로 둬서
# zero padding의 역할을 하게 둠
return seq_tensor
# Create necessary variables, lengths, and target
def make_variables(names):
sequence_and_length = [str2ascii_arr(name) for name in names]
# 각 이름들의 ascii code array와 그 length를 sequence_and_length에 할당
vectorized_seqs = [sl[0] for sl in sequence_and_length]
# vectorized_seqs에는 ascii code array
seq_lengths = torch.LongTensor([sl[1] for sl in sequence_and_length])
# seq_lengths에는 각 ascii code의 길이를 할당
return pad_sequences(vectorized_seqs, seq_lengths)
# zero padding 결과
if __name__ == '__main__':
# 해당 모듈을 직접 실행할 경우 __name__에 __main___이 저장되기 때문에 true, 아래 코드들이 실행됨
# 해당 모듈이 외부에서 모듈로 import되는 경우에는 __name__에 해당 모듈의 파일 이름이 저장되기 때문에
# false가 돼서 아래 코드들이 실행되지 않음. 따라서 아래 코드는 직접 실행되는 경우에만 실행됨
names = ['adylov', 'solan', 'hard', 'san']
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_CLASSES)
for name in names:
arr, _ = str2ascii_arr(name)
inp = Variable(torch.LongTensor([arr]))
out = classifier(inp)
print("in", inp.size(), "out", out.size())
inputs = make_variables(names)
out = classifier(inputs)
print("batch in", inputs.size(), "batch out", out.size())import time
import math
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from name_dataset import NameDataset
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
# Parameters and DataLoaders
HIDDEN_SIZE = 100
N_LAYERS = 2
BATCH_SIZE = 256
N_EPOCHS = 100
test_dataset = NameDataset(is_train_set=False)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE, shuffle=True)
train_dataset = NameDataset(is_train_set=True)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE, shuffle=True)
N_COUNTRIES = len(train_dataset.get_countries())
print(N_COUNTRIES, "countries")
N_CHARS = 128 # ASCII
# Some utility functions
def time_since(since):
s = time.time() - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def create_variable(tensor):
# Do cuda() before wrapping with variable
if torch.cuda.is_available():
return Variable(tensor.cuda())
else:
return Variable(tensor)
# pad sequences and sort the tensor
def pad_sequences(vectorized_seqs, seq_lengths, countries):
seq_tensor = torch.zeros((len(vectorized_seqs), seq_lengths.max())).long()
for idx, (seq, seq_len) in enumerate(zip(vectorized_seqs, seq_lengths)):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# Sort tensors by their length
seq_lengths, perm_idx = seq_lengths.sort(0, descending=True)
seq_tensor = seq_tensor[perm_idx]
# Also sort the target (countries) in the same order
target = countries2tensor(countries)
if len(countries):
target = target[perm_idx]
# Return variables
# DataParallel requires everything to be a Variable
return create_variable(seq_tensor), \
create_variable(seq_lengths), \
create_variable(target)
# Create necessary variables, lengths, and target
def make_variables(names, countries):
sequence_and_length = [str2ascii_arr(name) for name in names]
vectorized_seqs = [sl[0] for sl in sequence_and_length]
seq_lengths = torch.LongTensor([sl[1] for sl in sequence_and_length])
return pad_sequences(vectorized_seqs, seq_lengths, countries)
def str2ascii_arr(msg):
arr = [ord(c) for c in msg]
return arr, len(arr)
def countries2tensor(countries):
country_ids = [train_dataset.get_country_id(
country) for country in countries]
return torch.LongTensor(country_ids)
class RNNClassifier(nn.Module):
# Our model
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = int(bidirectional) + 1
# bidirectional이 True인 경우 int(bidirectional)이 1이기 때문에 direction = 2
# false인 경우 int(bidirectinal)이 0이기 때문에 direction = 1
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
bidirectional=bidirectional)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input, seq_lengths):
# Note: we run this all at once (over the whole input sequence)
# input shape: B x S (input size)
# transpose to make S(sequence) x B (batch)
input = input.t()
batch_size = input.size(1)
# Make a hidden
hidden = self._init_hidden(batch_size)
# Embedding S x B -> S x B x I (embedding size)
embedded = self.embedding(input)
# Pack them up nicely
gru_input = pack_padded_sequence(
embedded, seq_lengths.data.cpu().numpy())
# Packs a Tensor containing padded sequences of variable length.
# To compact weights again call flatten_parameters().
self.gru.flatten_parameters()
output, hidden = self.gru(gru_input, hidden)
# Use the last layer output as FC's input
# No need to unpack, since we are going to use hidden
fc_output = self.fc(hidden[-1]) # 마지막 hidden을 이용해 output생성
return fc_output
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions,
batch_size, self.hidden_size)
return create_variable(hidden)
# Train cycle
def train():
total_loss = 0
for i, (names, countries) in enumerate(train_loader, 1):
input, seq_lengths, target = make_variables(names, countries)
output = classifier(input, seq_lengths)
loss = criterion(output, target)
total_loss += loss.data[0]
classifier.zero_grad()
loss.backward()
optimizer.step()
if i % 10 == 0:
print('[{}] Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.2f}'.format(
time_since(start), epoch, i *
len(names), len(train_loader.dataset),
100. * i * len(names) / len(train_loader.dataset),
total_loss / i * len(names)))
return total_loss
# Testing cycle
def test(name=None):
# Predict for a given name
if name:
input, seq_lengths, target = make_variables([name], [])
output = classifier(input, seq_lengths)
pred = output.data.max(1, keepdim=True)[1]
# 18개의 Output value 중 제일 큰 값을 예측값으로 선정
country_id = pred.cpu().numpy()[0][0]
print(name, "is", train_dataset.get_country(country_id))
return
print("evaluating trained model ...")
correct = 0
train_data_size = len(test_loader.dataset)
for names, countries in test_loader:
input, seq_lengths, target = make_variables(names, countries)
output = classifier(input, seq_lengths)
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.0f}%)\n'.format(
correct, train_data_size, 100. * correct / train_data_size))
if __name__ == '__main__':
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRIES, N_LAYERS)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [33, xxx] -> [11, ...], [11, ...], [11, ...] on 3 GPUs
classifier = nn.DataParallel(classifier)
# 사용가능한 GPU가 여러 대라면 여러 대에 데이터 동일하게 분할하여 연산
if torch.cuda.is_available():
classifier.cuda()
optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
start = time.time()
print("Training for %d epochs..." % N_EPOCHS)
for epoch in range(1, N_EPOCHS + 1):
# Train cycle
train()
# Testing
test()
# Testing several samples
test("Sung")
test("Jungwoo")
test("Soojin")
test("Nako")import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from text_loader import TextDataset
hidden_size = 100
n_layers = 3
batch_size = 1
n_epochs = 100
n_characters = 128 # ASCII
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers)
self.linear = nn.Linear(hidden_size, output_size)
# This runs this one step at a time
# It's extremely slow, and please do not use in practice.
# We need to use (1) batch and (2) data parallelism
def forward(self, input, hidden):
embed = self.embedding(input.view(1, -1)) # S(=1) x I
embed = embed.view(1, 1, -1) # S(=1) x B(=1) x I (embedding size)
output, hidden = self.gru(embed, hidden)
output = self.linear(output.view(1, -1)) # S(=1) x I
return output, hidden
def init_hidden(self):
if torch.cuda.is_available():
hidden = torch.zeros(self.n_layers, 1, self.hidden_size).cuda()
else:
hidden = torch.zeros(self.n_layers, 1, self.hidden_size)
return Variable(hidden)
def str2tensor(string):
tensor = [ord(c) for c in string]
tensor = torch.LongTensor(tensor)
if torch.cuda.is_available():
tensor = tensor.cuda()
return Variable(tensor)
def generate(decoder, prime_str='A', predict_len=100, temperature=0.8):
hidden = decoder.init_hidden()
prime_input = str2tensor(prime_str)
predicted = prime_str
# Use priming string to "build up" hidden state
for p in range(len(prime_str) - 1):
_, hidden = decoder(prime_input[p], hidden)
inp = prime_input[-1]
for p in range(predict_len):
output, hidden = decoder(inp, hidden)
# Sample from the network as a multinomial distribution
output_dist = output.data.view(-1).div(temperature).exp()
top_i = torch.multinomial(output_dist, 1)[0]
# Add predicted character to string and use as next input
predicted_char = chr(top_i)
predicted += predicted_char
inp = str2tensor(predicted_char)
return predicted
# Train for a given src and target
# It feeds single string to demonstrate seq2seq
# It's extremely slow, and we need to use (1) batch and (2) data parallelism
# http://pytorch.org/tutorials/beginner/former_torchies/parallelism_tutorial.html.
def train_teacher_forching(line):
input = str2tensor(line[:-1])
target = str2tensor(line[1:])
hidden = decoder.init_hidden()
loss = 0
for c in range(len(input)):
output, hidden = decoder(input[c], hidden)
loss += criterion(output, target[c])
decoder.zero_grad()
loss.backward()
decoder_optimizer.step()
return loss.data[0] / len(input)
def train(line):
input = str2tensor(line[:-1])
target = str2tensor(line[1:])
hidden = decoder.init_hidden()
decoder_in = input[0]
loss = 0
for c in range(len(input)):
output, hidden = decoder(decoder_in, hidden)
loss += criterion(output, target[c])
decoder_in = output.max(1)[1]
decoder.zero_grad()
loss.backward()
decoder_optimizer.step()
return loss.data[0] / len(input)
if __name__ == '__main__':
decoder = RNN(n_characters, hidden_size, n_characters, n_layers)
if torch.cuda.is_available():
decoder.cuda()
decoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
train_loader = DataLoader(dataset=TextDataset(),
batch_size=batch_size,
shuffle=True)
print("Training for %d epochs..." % n_epochs)
for epoch in range(1, n_epochs + 1):
for i, (lines, _) in enumerate(train_loader):
loss = train(lines[0]) # Batch size is 1
if i % 100 == 0:
print('[(%d %d%%) loss: %.4f]' %
(epoch, epoch / n_epochs * 100, loss))
print(generate(decoder, 'Wh', 100), '\n')# Original source from
# https://gist.github.com/Tushar-N/dfca335e370a2bc3bc79876e6270099e
# torch
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
import torch.nn.functional as F
import numpy as np
import itertools
def flatten(l):
return list(itertools.chain.from_iterable(l))
# # Importing chain class from itertools
# from itertools import chain
# # Single iterable containing iterable
# # elements(strings) is passed as input
# from_iterable = chain.from_iterable(['geeks',
# 'for',
# 'geeks'])
# # printing the flattened iterable
# print(list(from_iterable))
# 즉 l의 모든 char가 ,로 분리되어 return됨
seqs = ['ghatmasala', 'nicela', 'chutpakodas']
# make <pad> idx 0
vocab = ['<pad>'] + sorted(list(set(flatten(seqs))))
# set을 하면 flatten(seqs) 중 unique한 char만 return 후 list로 만들고 sort
# 제일 앞에 Padding token 삽입해서 vocab 정의
# make model
embedding_size = 3
embed = nn.Embedding(len(vocab), embedding_size)
lstm = nn.LSTM(embedding_size, 5)
# hidden_size = 5
vectorized_seqs = [[vocab.index(tok) for tok in seq]for seq in seqs]
print("vectorized_seqs", vectorized_seqs)
print([x for x in map(len, vectorized_seqs)])
# get the length of each seq in your batch
# map함수 이용해서 vectorized_seqs에 len함수 적용
seq_lengths = torch.LongTensor([x for x in map(len, vectorized_seqs)])
# dump padding everywhere, and place seqs on the left.
# NOTE: you only need a tensor as big as your longest sequence
seq_tensor = Variable(torch.zeros(
(len(vectorized_seqs), seq_lengths.max()))).long()
for idx, (seq, seqlen) in enumerate(zip(vectorized_seqs, seq_lengths)):
seq_tensor[idx, :seqlen] = torch.LongTensor(seq)
print("seq_tensor", seq_tensor)
# SORT YOUR TENSORS BY LENGTH!
seq_lengths, perm_idx = seq_lengths.sort(0, descending=True)
seq_tensor = seq_tensor[perm_idx]
print("seq_tensor after sorting", seq_tensor)
# utils.rnn lets you give (B,L,D) tensors where B is the batch size,
# L is the maxlength, if you use batch_first=True
# Otherwise, give (L,B,D) tensors
seq_tensor = seq_tensor.transpose(0, 1) # (B,L,D) -> (L,B,D)
print("seq_tensor after transposing", seq_tensor.size(), seq_tensor.data)
# embed your sequences
embeded_seq_tensor = embed(seq_tensor)
print("seq_tensor after embeding", embeded_seq_tensor.size(), seq_tensor.data)
# pack them up nicely
packed_input = pack_padded_sequence(
embeded_seq_tensor, seq_lengths.cpu().numpy())
# packs a tensor containing padded sequences of varaible length
# throw them through your LSTM (remember to give batch_first=True here if
# you packed with it)
packed_output, (ht, ct) = lstm(packed_input)
# Outputs: output, (h_n, c_n)
# output: containing the output features (h_t) from the last layer of the LSTM, for each t
# ht: final hidden state for each element in the sequence
# ct: final cell state for each element in the sequence
# unpack your output if required
output, _ = pad_packed_sequence(packed_output)
print("Lstm output", output.size(), output.data)
# Or if you just want the final hidden state?
print("Last output", ht[-1].size(), ht[-1].data)'ML \ DL > PyTorch Zero To All' 카테고리의 다른 글
| PyTorch Lecture 12: RNN (0) | 2022.08.09 |
|---|---|
| PyTorch Lecture 11: Advanced CNN (0) | 2022.08.05 |
| PyTorch Lecture 10: Basic CNN (0) | 2022.07.26 |
| PyTorch Lecture 09: Softmax Classifier (0) | 2022.07.14 |
| PyTorch Lecture 06: Logistic Regression (0) | 2022.07.13 |