방학동안 학회에서 김성훈 교수님의 PyTorch Zero To All 강의로 공부를 하게 된 김에 스스로 정리해보려고 합니다.
좋은 강의 공유해주신 김성훈 교수님께 감사드립니다.
강의링크:
https://www.youtube.com/playlist?list=PLlMkM4tgfjnJ3I-dbhO9JTw7gNty6o_2m
PyTorchZeroToAll (in English)
Basic ML/DL lectures using PyTorch in English.
www.youtube.com
RNN은 텍스트, 음성 데이터와 같이 순서가 있는 Sequence Data를 다루기에 적합한 Neural Network입니다.
Sequence Data란 말 그대로 순서가 있는 데이터를 의미하는데, 해당 데이터는 순서가 있기 때문에 원소들 간의 관계가 독립적이지 못합니다. 이러한 특징을 RNN은 'hidden state'를 통해 모델에 충분히 반영합니다.
RNN은 다음과 같은 구조를 가지고 있습니다.

RNN의 hidden layer에서의 연산결과가 단순히 output으로만 출력이 되는 것이 아니라 다음 hidden layer로도 전달되고 있습니다. 이러한 RNN의 구조 덕에, 우리는 이전까지의 정보들을 다음 output을 산출하는데에도 사용할 수 있게 됩니다.
이러한 특징 때문에 RNN(Recurrent Neural Network), 순환신경망이라고 불립니다.
이런 특징 덕에, 앞서 언급했듯, RNN은 다음과 같은 task를 수행하기 위하여 사용됩니다.
RNN의 구조를 조금 더 자세하게 살펴보면 위의 그림과 같습니다. Input xt−2와 이전 hidden state, Ht−2를 hidden layer에 입력하여 나온 hidden state Ht−1를 복사하여 각각 output layer, 그리고 다음 hidden layer에 전달하고, 다시 해당 hidden state와 새로운 input을 이용하여 새로운 output을 만들어냅니다.

RNN의 입력과 출력은 저희가 원하는 방향으로 자유롭게 조정 가능합니다. 다음은 그 몇 가지 예시입니다.

1. One to one: hidden state를 가지고 있지 않기 때문에 RNN이 아닙니다.
2. One to many 예) 하나의 이미지를 input으로 받아 여러가지 캡션(설명)을 만들어내는 Image Captioning
3. Many to one 예) 여러 단어 혹은 문장을 input으로 받아 어떤 감정인지 분석하는 Text Sentiment Analysis

4. Many to many 예) A언어로 된 여러 문장을 Input으로 받아 원하는 언어 B로 번역
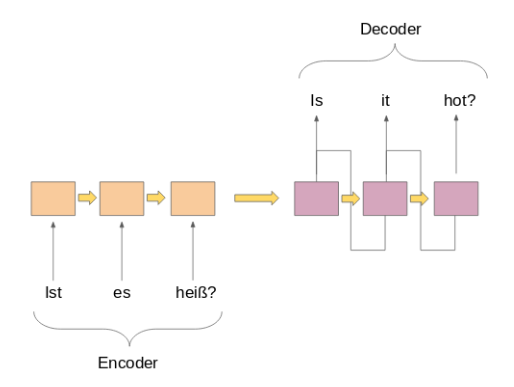
5. Many to many 예) 문장의 다음 언어를 예측하는 모델
import torch
import torch.nn as nn
from torch.autograd import Variable
# One hot encoding for each char in 'hello'
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
# 컴퓨터에 언어를 바로 전달하면 컴퓨터는 이를 이해하지 못하기 때문에, one hot encoding을 통해
# numerical value로 바꾸어 전달해줍니다. 이때, one hot encoding의 결과의 수는 원하는 단어/문장의
# unique한 character/word의 수에 해당합니다.
# One cell RNN input_dim (4) -> output_dim (2). sequence: 5
cell = nn.RNN(input_size=4, hidden_size=2, batch_first=True)
# input_size = one-hot size = 4
# hidden_state는 저희가 설정할 수 있는 hyperparameter입니다.
# batch_first = True 옵션을 통해 input과 output tensor가 (seq, batch, feature)의 모양이
# 아닌 (batch, seq, feature)의 모양으로 제공됩니다.
# seq는 input에 한번에 전달하는 단어 혹은 문장의 수를 의미합니다.
# feature은 output dimension과 동일합니다.
# (num_layers * num_directions, batch, hidden_size) whether batch_first=True or False
hidden = Variable(torch.randn(1, 1, 2))
# 해당 예시에서 사용하는 layer는 하나이기 때문에 1, num_directions = 1
# 교수님이 direction에 대한 자세한 설명은 후에 해주신다고 하셨기 때문에, 이것은 일단 넘어가겠습니다.
# hidden_size = output_dim
# Propagate input through RNN
# Input: (batch, seq_len, input_size) when batch_first=True
inputs = Variable(torch.Tensor([h, e, l, l, o]))
for one in inputs:
one = one.view(1, 1, -1)
# input으로 한번에 h, e, l, l, o와 같은 식으로 하나의 char만을 받음
# Input: (batch, seq_len, input_size) when batch_first=True
out, hidden = cell(one, hidden)
print("one input size", one.size(), "out size", out.size())
# We can do the whole at once
# Propagate input through RNN
# Input: (batch, seq_len, input_size) when batch_first=True
inputs = inputs.view(1, 5, -1)
# input_size는 4, -1 -> 4 h,e,l,o의 4개의 unique한 character를 갖기 때문에
# 위처럼 한번에 하나의 char을 받는 것이 아니라 5개의 char로 이루어진 hello, 한 단어를 받음
out, hidden = cell(inputs, hidden)
print("sequence input size", inputs.size(), "out size", out.size())
# hidden : (num_layers * num_directions, batch, hidden_size) whether batch_first=True or False
hidden = Variable(torch.randn(1, 3, 2))
# One cell RNN input_dim (4) -> output_dim (2). sequence: 5, batch 3
# 3 batches 'hello', 'eolll', 'lleel'
# rank = (3, 5, 4)
inputs = Variable(torch.Tensor([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]]))
# Propagate input through RNN
# Input: (batch, seq_len, input_size) when batch_first=True
# B x S x I
out, hidden = cell(inputs, hidden)
print("batch input size", inputs.size(), "out size", out.size())
# One cell RNN input_dim (4) -> output_dim (2)
cell = nn.RNN(input_size=4, hidden_size=2)
# The given dimensions dim0 and dim1 are swapped.
inputs = inputs.transpose(dim0=0, dim1=1)
# Propagate input through RNN
# Input: (seq_len, batch_size, input_size) when batch_first=False (default)
# S x B x I
out, hidden = cell(inputs, hidden)
print("batch input size", inputs.size(), "out size", out.size())# Lab 12 RNN
import sys
import torch
import torch.nn as nn
from torch.autograd import Variable
torch.manual_seed(777) # reproducibility
# 결과가 매번 달라지지 않게 random seed 고정
# 0 1 2 3 4
idx2char = ['h', 'i', 'e', 'l', 'o']
# Teach hihell -> ihello
x_data = [0, 1, 0, 2, 3, 3] # hihell
one_hot_lookup = [[1, 0, 0, 0, 0], # 0
[0, 1, 0, 0, 0], # 1
[0, 0, 1, 0, 0], # 2
[0, 0, 0, 1, 0], # 3
[0, 0, 0, 0, 1]] # 4
y_data = [1, 0, 2, 3, 3, 4] # ihello
x_one_hot = [one_hot_lookup[x] for x in x_data]
# 위의 코드블럭처럼 각 char마다 일일히 지정하는 것보다는
# 위와 같은 방식을 취하는 것이 바람직함
# As we have one batch of samples, we will change them to variables only once
inputs = Variable(torch.Tensor(x_one_hot))
labels = Variable(torch.LongTensor(y_data))
num_classes = 5
input_size = 5 # one-hot size: h, i, e, l, o의 5가지
hidden_size = 5 # output from the RNN. 5 to directly predict one-hot
batch_size = 1 # one sentence
sequence_length = 1 # One by one
num_layers = 1 # one-layer rnn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size, batch_first=True)
def forward(self, hidden, x):
# Reshape input (batch first)
x = x.view(batch_size, sequence_length, input_size)
# Propagate input through RNN
# Input: (batch, seq_len, input_size)
# hidden: (num_layers * num_directions, batch, hidden_size)
out, hidden = self.rnn(x, hidden)
return hidden, out.view(-1, num_classes)
def init_hidden(self):
# Initialize hidden and cell states
# (num_layers * num_directions, batch, hidden_size)
return Variable(torch.zeros(num_layers, batch_size, hidden_size))
# Instantiate RNN model
model = Model()
print(model)
# Set loss and optimizer function
# CrossEntropyLoss = LogSoftmax + NLLLoss
criterion = nn.CrossEntropyLoss()
# Multi-label classification이라고 봐도 무방하기 때문에 cross entropy loss 사용
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# Train the model
for epoch in range(100):
optimizer.zero_grad()
loss = 0
hidden = model.init_hidden()
sys.stdout.write("predicted string: ")
# 현재 여기서는 Print와 거의 동일한 역할을 하고 있다고 봐도 무방, 하지만 \n은 없음
for input, label in zip(inputs, labels):
# print(input.size(), label.size())
hidden, output = model(hidden, input)
val, idx = output.max(1)
sys.stdout.write(idx2char[idx.data[0]])
loss += criterion(output, torch.LongTensor([label]))
print(", epoch: %d, loss: %1.3f" % (epoch + 1, loss))
loss.backward() # 역전파 계산
optimizer.step() # gradient update
print("Learning finished!")# Lab 12 RNN
import torch
import torch.nn as nn
from torch.autograd import Variable
torch.manual_seed(777) # reproducibility
idx2char = ['h', 'i', 'e', 'l', 'o']
# Teach hihell -> ihello
x_data = [[0, 1, 0, 2, 3, 3]] # hihell
x_one_hot = [[[1, 0, 0, 0, 0], # h 0
[0, 1, 0, 0, 0], # i 1
[1, 0, 0, 0, 0], # h 0
[0, 0, 1, 0, 0], # e 2
[0, 0, 0, 1, 0], # l 3
[0, 0, 0, 1, 0]]] # l 3
y_data = [1, 0, 2, 3, 3, 4] # ihello
# As we have one batch of samples, we will change them to variables only once
inputs = Variable(torch.Tensor(x_one_hot))
labels = Variable(torch.LongTensor(y_data))
num_classes = 5
input_size = 5 # one-hot size
hidden_size = 5 # output from the LSTM. 5 to directly predict one-hot
batch_size = 1 # one sentence
sequence_length = 6 # |ihello| == 6
num_layers = 1 # one-layer rnn
class RNN(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(RNN, self).__init__()
self.num_classes = num_classes
self.num_layers = num_layers
self.input_size = input_size
self.hidden_size = hidden_size
self.sequence_length = sequence_length
self.rnn = nn.RNN(input_size=5, hidden_size=5, batch_first=True)
def forward(self, x):
# Initialize hidden and cell states
# (num_layers * num_directions, batch, hidden_size) for batch_first=True
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size))
# 첫번째 layer에도 hidden state가 요구되기 때문에 hidden state를 initialize 해주어야함
# Reshape input
x.view(x.size(0), self.sequence_length, self.input_size)
# Propagate input through RNN
# Input: (batch, seq_len, input_size)
# h_0: (num_layers * num_directions, batch, hidden_size)
out, _ = self.rnn(x, h_0)
return out.view(-1, num_classes)
# Instantiate RNN model
rnn = RNN(num_classes, input_size, hidden_size, num_layers)
print(rnn)
# Set loss and optimizer function
# CrossEntropyLoss = LogSoftmax + NLLLoss
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.1)
# Train the model
for epoch in range(100):
outputs = rnn(inputs)
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(1)
idx = idx.data.numpy()
result_str = [idx2char[c] for c in idx.squeeze()]
print("epoch: %d, loss: %1.3f" % (epoch + 1, loss.data[0]))
print("Predicted string: ", ''.join(result_str))
print("Learning finished!")
'ML \ DL > PyTorch Zero To All' 카테고리의 다른 글
| RNN II (Classification) (0) | 2022.08.14 |
|---|---|
| PyTorch Lecture 11: Advanced CNN (0) | 2022.08.05 |
| PyTorch Lecture 10: Basic CNN (0) | 2022.07.26 |
| PyTorch Lecture 09: Softmax Classifier (0) | 2022.07.14 |
| PyTorch Lecture 06: Logistic Regression (0) | 2022.07.13 |