Efficient Estimation of Word Representations in Vector Space
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best per
arxiv.org
저자: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
Introduction
논문이 쓰였을 당시, 많은 NLP system과 technique들은 단어를 atomic unit(one hot vector 방식을 말하는 것 같다)으로 다루었고, 따라서, 단어들 간의 유사도를 표현할 수 있는 방법이 존재하지 않았다. One hot vector를 이용하여 단어를 표현하는 것은 simple, robust하다는 장점은 물론, 이런 simple한 model을 large data에 훈련 시키는 것이 오히려 complex한 모델을 less data에 훈련시키는 것보다 성능이 좋다는 점 때문에 선호되기도 한다.
하지만, domain이나 task에 따라, 이러한 large data의 사용이 제한되는 경우가 많고, 따라서 more advanced techique이 필요하게 된다. 또한 머신러닝 기술의 발전으로 complex model을 large data에 훈련시키는 것이 가능해졌고, 이 방법이 보통 simple model을 사용하는 편보다 성능이 우수하기 때문에 보다 complex/advanced한 모델이 필요로 하게 되었다.
따라서, 해당 논문에서는 굉장히 큰 데이터에 대해서도 단어들을 continuous vector로 표현할 수 있게 하는 2개의 새로운 model architecture를 소개하려고 한다. 2개의 모델들을 통해 accuracy의 대폭 상승 뿐 아니라 computational cost마저 줄일 수 있었다고 한다. 그 외에도 논문에서 소개하고 있는 모델은 비슷한 단어들을 가까이 위치시키는 것을 넘어 단어들이 multiple degrees of similarity를 갖는 것도 가능하게 한다. 심지어 이렇게 생성한 word vector들은 vector("King") - vector("Man") + vector("Woman") ≈≈ vector("Queen")과 같은 연산 또한 가능하다.
Model Architectures
다양한 model architecture들을 서로 비교하기 위하여, 우선 mode의 computational complexity(Q)를 model을 훈련하기 위해 필요한 parameter의 수로 정의한다. 우리의 목표는 accuracy는 최대화하면서 computational complexity는 최소가 되게끔 하는 것이다. Training complexity는 아래에 비례한다.
O=E×T×QO=E×T×Q
* E = # of training epochs
* T = number of words in the training set
* Q = 각 모델의 특성에 따라 결정
일반적으로 E = 3 ~ 50, T는 최대 10억개까지 고려된다. 모든 모델들은 stochastic gradient descent와 backpropagation을 이용하여 학습된다.
Feed Forward Neural Net Language Model (NNLM)
Feedforward neural network language model은 input, projection, hidden, output layer로 이루어져있다.

Input layer는 one hot encoding된(vocabulary size V 크기의 vector) N개의 word vector들이 input으로 들어가게 된다. 이 때 N은 n-gram모델에서 다음 단어 예측을 위해 사용하는 이전 단어의 수이다. Input layer는 V X D의 projection matrix(이를 흔히 look-up table이라 부름)를 거쳐 N X D의 크기를 갖는 projection layer에 projection 된다. Projection layer는 N X D X H의 matrix를 거쳐 N X D X H 크기의 가중치 WhWh와 곱해진 후 활성화 함수를 통과해 hidden layer에 출력된다. 마지막으로 hidden layer는 H X V 크기의 가중치 WoWo와 곱해진 후 softmax function을 통과해 특정 확률값의 형태로 표현되고, cross entropy loss를 이용하여 실제 단어의 one hot vector와 가까워지도록 학습되게 된다.
따라서 최종적으로 NNLM의 computational complexity Q는
Q=N×D+N×D×H+H×VQ=N×D+N×D×H+H×V
가 된다. 이때, 일반적으로 N = 10, D = 500 ~ 2000, H = 500 ~ 1000 정도의 크기를 지닌다고 한다.
* 처음에는 Q의 첫번째 term이 N×DN×D가 아닌 V×DV×D여야 한다고 생각했는데, N×DN×D인 이유는 아래와 같다고 한다. V개의 단어가 있다면, 당연히 input은 1-of-V one hot vector일 것이다. 그리고 만약 N개의 단어가 input으로 주어진다면, input matrix는 N×VN×V의 사이즈를 가지게 될 것이다. 하지만, NNLM은 n-gram 모델이기 때문에, 매 time마다 오직 N개의 단어만이 주어지고, 따라서 projection matrix의 V개의 matrix element 중 N개만이 주어진 time에 참조 및 업데이트 되게 된다. 따라서 주어진 시간에, input matrix의 차원은 N×VN×V가 아닌 N×NN×N이 되고, 따라서 WpWp는 N×N×N×D=N×DN×N×N×D=N×D가 된다. 따라서 computational complexity Q는 Q=N×D+N×D×H+H×VQ=N×D+N×D×H+H×V가 된다.
NNLM의 computational complexity Q에서 dominating term은 H×VH×V이다. 하지만 H×VH×V에서의 computational complexity는 Huffman tree based hierarachical softmax를 이용하여 H×log2(V)H×log2(V)로 줄이는 것이 가능하다. 따라서 feedforward NNLM의 computational complexity은 대부분 N×D×H에서 오게 된다.
* Huffman tree란?
허프만 코딩(Huffman coding)은 텍스트 압축을 위해 널리 사용되는 방법으로, 원본 데이터에서 자주 출현하는 문자는 적은 비트의 코드로 변환하여 표현하고 출현 빈도가 낮은 문자는 많은 비트의 코드로 변환하여 표현함으로써 전체 데이터를 표현하는데 필요한 비트 수를 줄이는 방식이다. 간단히 설명하여 자주 등장하는 단어에 대해서는 접근성을 높이고, 자주 등장하지 않는 단어에 대해서는 접근성을 낮추는 방식을 취한다.
https://www.youtube.com/watch?v=dM6us854Jk0&t=131s
* Hierarchical softmax란?
기존 softmax의 계산량을 현격히 줄인, softmax에 근사시키는 방법론이다.

https://www.youtube.com/watch?v=pzyIWCelt_E
Recurrent Neural Net Language Model(RNNLM)
Feedforward NNLM의 한계를 극복하기 위해 RNNLM들이 제시되었다. RNNLM들은 projection layer는 존재하지 않고, input, hidden, output layer로만 구성되어있다. 다만, hidden layer가 다시 hidden layer의 input으로 들어가는 recurrent한 구조를 가지고 있다. 이 덕분에 RNN은 이전 timestep의 memory를 뒤로 넘겨주는 것이 가능하다.

RNN 모델의 computational complexity Q는 다음과 같다.
Q=H×H+H×V
H×H는 이전 hidden layer에서 다음 hidden layer로 갈 때의 연산, H×V는 hidden layer에서 output layer에서의 연산에서 비롯된다. NNLM에서와 마찬가지로 hierarchical softmax를 이용하여 H×V를 H×log2(V)로 줄일 수 있다. 따라서 RNNLM의 complexity의 대부분은 H×H에서 비롯된다.
New Log-linear Models
Computational complexity를 최소화하면서 distributed representations of words를 학습할 수 있는 새로운 model architecture를 2개 제시하고자 한다. 이전에 살펴본 기존 모델들의 연산의 복잡성이 non-linear hidden layer 때문이란 것을 확인할 수 있었다. 이러한 사실은 단어 표현의 정확도를 줄이더라도 더욱 효율적인 훈련이 가능한 모델에 대하여 연구의 필요성을 가져왔다.
본 논문에서 제안하는 새로운 모델의 훈련은 두 단계로 이루어진다. 첫째, 단순한 모델을 이용하여 continuous word vector가 학습된다. 그리고 이런 distributed representations of words를 이용하여 N-gram NNLM이 훈련된다.
Continuous Bag-of-Words Model
첫번째 모델은 CBOW(continuous bag-of-words)이다. CBOW는 non-linear한 hidden layer가 제거되고 모든 단어가 projection layer를 공유하고 있는 형태의 feedforward NNLM과 비슷하다. 모든 단어가 같은 position으로 projection되기 때문에, 단어의 순서가 projection에 영향을 끼치지 않아 bag of words라 불린다. continuous bag of words라 불리는 이유는 bag of words와는 다르게 continuous distributed representation of words를 사용하기 때문이다.
CBOW의 projection layer는 아래의 그림에서 볼 수 있듯이, 가중치와 input word의 계산 결과를 평균 내는 역할을 한다. 따라서 순서가 중요하지 않은 것이다.
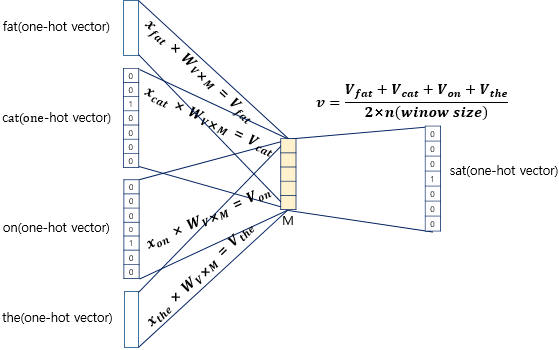
추가로 CBOW에서는 이전 단어 뿐 아니라 미래 단어들도 사용한다. 즉, 이전 단어들과 미래의 단어들을 이용하여 가운데 단어를 예측하는 task를 수행하게 된다. 위의 그림을 보면 fat cat sat on the가 original context인데, 이전 단어인 fat, cat과 미래의 단어인 on, the를 이용하여 sat을 예측하고 있는 것을 확인할 수 있다.
CBOW는 NNLM과는 달리 hidden layer가 존재하지 않기에, computational complexity Q는 다음과 같다.
Q=N×D+D×log2(V)
다음은 논문에서 소개하는 2번째 모델인 Skip-gram이다.
Continuous Skip-gram Model
이전 단어들과 미래의 단어들을 이용하여 중심 단어를 예측하는 CBOW와는 다르게 Skip-gram은 중심 단어를 이용하여 이전 단어들과 미래의 단어들에 대한 예측을 진행한다. 중심 단어에 대해서 그 주변 단어를 예측하므로 CBOW와는 다르게 projection layer에서 벡터들의 평균을 구하는 과정은 따로 존재하지 않는다. 중심 단어에서부터 멀리 떨어져있는 단어는 가까이 위치한 단어보다 중심 단어와의 관련도가 떨어질 확률이 크기 때문에, 훈련 과정에서 적은 가중치를 주어 훈련하게 된다고 한다.

여러 논문에서 성능 비교를 진행했을 때 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 한다. 얼핏 봤을 때는 주변 단어들을 이용하여 중심 단어를 예측하는 CBOW가 중심 단어 하나만을 이용하여 주변 단어들을 예측하려고 하는 Skip-gram보다 비교적 수월한 task를 수행하고 있기 때문에 CBOW의 성능이 당연히 더 좋을 것만 같다. 이는 gradient flow의 관점에서 봤을 때, CBOW는 하나의 gradient(중심단어)가 각각의 주변 단어들을 업데이트 하기 위해 쓰이는 반면에 skip-gram은 주변 단어들의 정보들이 모두 하나의 gradient를 update하기 위해 사용되기 때문이라고 볼 수 있다.
추가로, 여러 개의 주변 단어들에 대한 예측을 진행하기 때문에 당연하게도 연산량은 CBOW에 비해 많다. 하지만 projection layer에서 input vector들을 평균을 내어 사용하는 CBOW와는 다르게 skip-gram은 input vector를 그대로 사용하기 때문에 low frequency를 가지는 word들에 대해 CBOW 대비 train 효과가 크다는 장점 또한 가진다. CBOW에서는 각 word vector들을 평균내서 사용하기 때문에 등장 빈도가 낮은 word들은 제대로 된 학습을 기대하기 힘들다.
Skip-gram의 computational complexity Q는 다음과 같다.
Q=C×(D+D×log2(V))
한 개의 input vector가 projection layer를 통과할 때의 연산 D, projection layer에서 output layer로의 연산 D×log2(V)와 이를 각각의 context word(주변 단어)들에 대해 수행해야하기 때문에 주변 단어들의 수인 C를 곱해주게 된다.
Results
해당 논문 이전에 word embedding의 성능을 측정은 단순히 유사한 word를 찾아내는 것을 통해 측정되었다. 예를 들어 “France”와 “Italy”가 유사한지를 측정하는 방법이다. 본 논문에서는 이러한 방식에서 나아가 단어들이 서로 어떻게 유사한지를 뽑아내 다양한 종류의 유사도를 word embedding이 잘 나타내는지를 확인하였다. 예를 들어 big-biggest와 같은 관계를 갖는 단어가 무엇인지를 small에 대해 찾는다면 smallest가 될 것이고, big-bigger와 같은 관계를 갖는 단어가 무엇인지를 small 대해서 찾는다면, 이때는 smallest가 아닌 smaller가 될 것이다. 본 논문에서 제시한 model로 학습된 word vector는 단순한 algebraic operation으로 이러한 관계를 확인할 수 있었다. X = vector(biggest) - vector(big) + vector(small)를 연산한 이후 코사인 유사도를 통해 가장 유사한 vector를 찾는다면 vector(smallest)가 나올 것이다. 이러한 semantic한 관계까지 제대로 표현할 수 있는 word vector를 사용함을 통해 기계 번역, information retrieval, QA system과 같은 다양한 NLP task에서 뛰어난 성능 향상을 기대할 수 있다.
Task Description
Word vector의 quality를 측정하기 위해 5 종류의 semantic question(8869개)과 9 종류의 syntactic question(10675개)으로 구성된 comprehensive test를 정의한다. 질문들은 다음과 같은 두 과정을 통해 생성되었다.
- 유사한 단어 쌍의 list를 수동적으로 생성한다.
- 랜덤하게 2개의 단어들을 짝 지어 question을 생성한다.
예를 들어 미국 도시 68개와 해당 도시가 속한 주를 연결하고, 랜덤하게 두 개의 단어 쌍을 선택해 약 2.5K개의 질의를 만들었다. 본 논문의 test set에는 단일 단어로 구성된 단어들만을 사용해 New York과 같이 2개 이상의 단어로 구성된 단어는 제외되었다.
연산 이후에 찾은 closest word가 정확히 기대되는 단어와 일치할 때만 질문에 올바르게 답하였다고 평가하였다. closest word가 synonym으로 나올 때 역시 오답으로 측정되었기에, 100% accuray를 보이는 것은 불가능에 가깝다고 할 수 있다.
Maximization of Accuracy
word vector를 학습시키기 위해 사용된 데이터는 Google의 news corpus이다. 해당 corpus는 대략 6B개의 token을 가지고 있다. 이 중 가장 frequent한 100만 개의 단어만을 사용하여 vocabualry size를 제한하였다. 높은 accuracy를 얻는 것도 중요하지만, 너무 오랜 시간을 소요하면 안되기 때문에, 빠른 시간 내에 좋은 결과를 얻기 위해서 최초에는 가장 많이 쓰이는 3만 개의 단어들이 포함된 question들만을 이용하여 평가를 진행하였다.
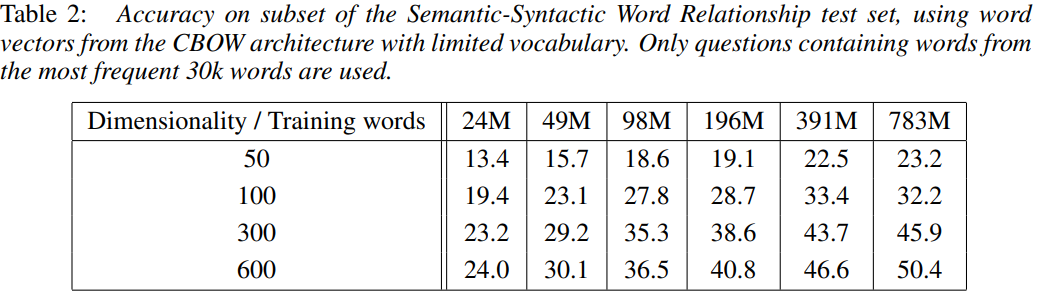
word vector의 dimension과 training words의 수를 바꾸어가며 실험을 진행했다. dimensionality나 training words의 수 중 하나를 고정시켰을 때는, 다른 하나를 증가시켜도 accuracy의 증가폭이 점점 감소하기에, 따라서 dimensionality와 training words의 수 모두 증가시켜야함을 확인할 수 있었다.
Comparison of Model Architectures

RNN을 통해 학습된 word vector가 syntactic question에 대해서는 어느 정도 괜찮은 성능을 보인 반면에, semantic question에 대해서는 성능이 굉장히 떨어지는 것을 볼 수 있다. NNLM의 경우 semantic question과 syntactic question 모두에 대해 RNN보다 우수한 성능을 보이고 있다.
CBOW를 사용한 경우 semantic question에서는 NNLM과 거의 유사한 성능을 보이지만, syntactic question에 대해서는 보다 우수한 성능을 보이는 것을 확인할 수 있다. 마지막으로 Skip-gram을 사용하였을 때는, syntactic question에 대해서는 CBOW보다 소폭 성능이 떨어지는 모습을 보이지만, semantic question에 대해서는 훨신 우수한 성능을 보이는 것을 확인할 수 있다.
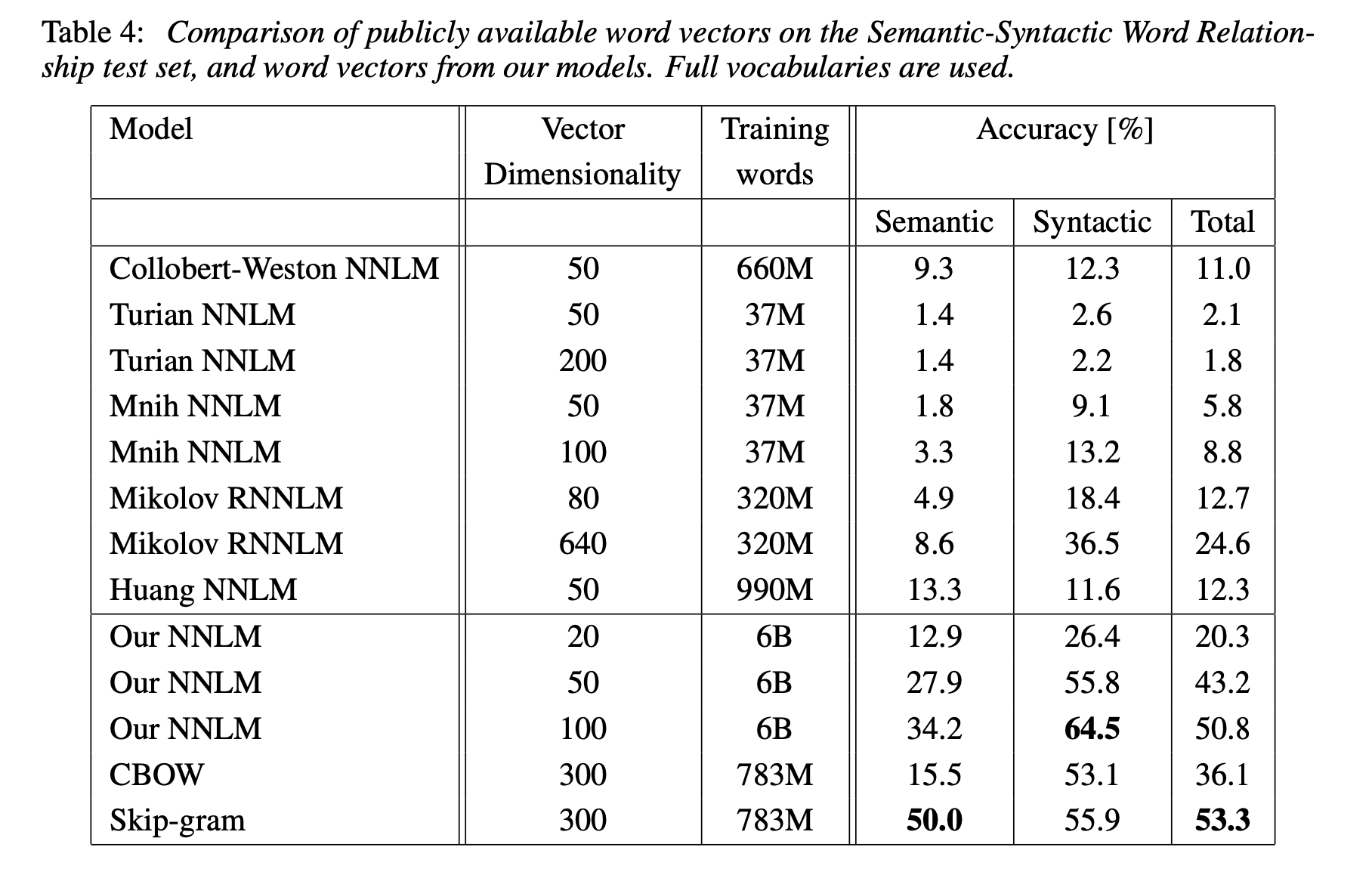
다음으로, 소개된 모델들을 한 개의 CPU만을 사용하여 학습한 결과를, publicly available한 word vector들과 비교하였을 때 역시 기존의 word vector들과 비교하였을 때, CBOW와 Skip-gram의 성능이 우수한 것을 확인할 수 있다.
추가적으로 1epoch + 두 배의 데이터를 사용했을 때(이 때, learning rate를 선형적으로 줄여 나가 훈련이 끝날 때쯤에는 learing rate가 0이 되게끔 하였다), 동일한 데이터에 3 epoch을 이용하여 훈련한 결과보다 더욱 좋은 결과를 내면서, 소폭의 속도 상승까지 가져옴을 다음과 같이 확인할 수 있었다.

Examples of the Learned Relationships
앞서 설명한 방법들을 이용하여 실험을 돌린 결과 얻은 word embedding을 통해 단어들의 관계를 잘 파악하고 있는지 확인한 결과이다.

- Paris - France + Italy = Rome
- Bigger - Big + Colder = Cold
와 같이 살짝 아쉬운 결과를 보이는 것도 있긴 하지만 전반적으로 좋은 결과를 보이고 있는 것을 확인할 수 있다. 만약 해당 논문에서 사용한 데이터셋보다 더욱 큰 데이터셋과 더욱 큰 차원을 이용하여 학습을 할 수 있다면, 성능이 더 좋아질 것이라 기대해도 좋을 것이다.
Conclusion
feedforward network나 RNN 모델과 같이 기존에 알려진 비교적 복잡한 모델들보다도 간단한 모델을 이용하여, 더욱 quality of vector representation of words가 우수하도록 할 수 있었다. 이를 통한 lower computational complexity 덕에, 더욱 큰 데이터셋을 이용하여, 더욱 고차원의 word vector를 학습할 수 있었다.
https://www.youtube.com/watch?v=sidPSG-EVDo&t=1283s
https://www.youtube.com/watch?v=s2KePv-OxZM
https://www.youtube.com/watch?v=sY4YyacSsLc
https://www.youtube.com/watch?v=rmVRLeJRkl4&list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ
'ML \ DL > Paper Reviews' 카테고리의 다른 글
| Attention is all you need (0) | 2023.03.24 |
|---|---|
| DIFFUSEQ: Sequence To Sequence Text Generation with Diffusion Models (0) | 2023.01.23 |
| Attention Is All You Need (0) | 2022.12.01 |
| Long Short-Term Memory (0) | 2022.11.11 |
| Latent Dirichlet Allocation (0) | 2022.11.03 |