저자: Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, Lingpeng Kong
Introduction
기존의 생성모델인 GAN, VAE, Flow-based models는 다양한 분야에서 우수한 성능을 보이고 있긴 하지만 여전히 한계가 존재한다.
GAN은 adversarial learning으로 인한 훈련의 불안정성이 존재하고, mode collapse(generator가 다양한 data를 생성해내지 못하고, 반복해서 비슷한 data만 계속 생성하는 문제)와 같은 문제도 존재한다.
VAE는 surrogate loss에 의존한다.
Flow-based models는 reversible transform을 위해서 특수한 architecture를 사용해야만 한다.
Diffusion Model은 non-equilibrium thermodynamics(비평형 열역학)에서 영감을 받은 모델로, forward process에서 Markov 체인을 정의하여 random noise를 데이터에 천천히 추가하고 이를 반대로 하는 reverse process에서는 noise에서 원하는 데이터 샘플을 생성하는 방법을 학습하여 데이터를 생성한다. Diffusion Model은 앞서 언급한 생성 모델들의 문제점을 일부 회피하고 우수 성능을 보이고 있음에도 text의 discrete한 성질 때문에 적용이 어려워 NLP에서는 아직 충분히 쓰이지 못하고 있다.
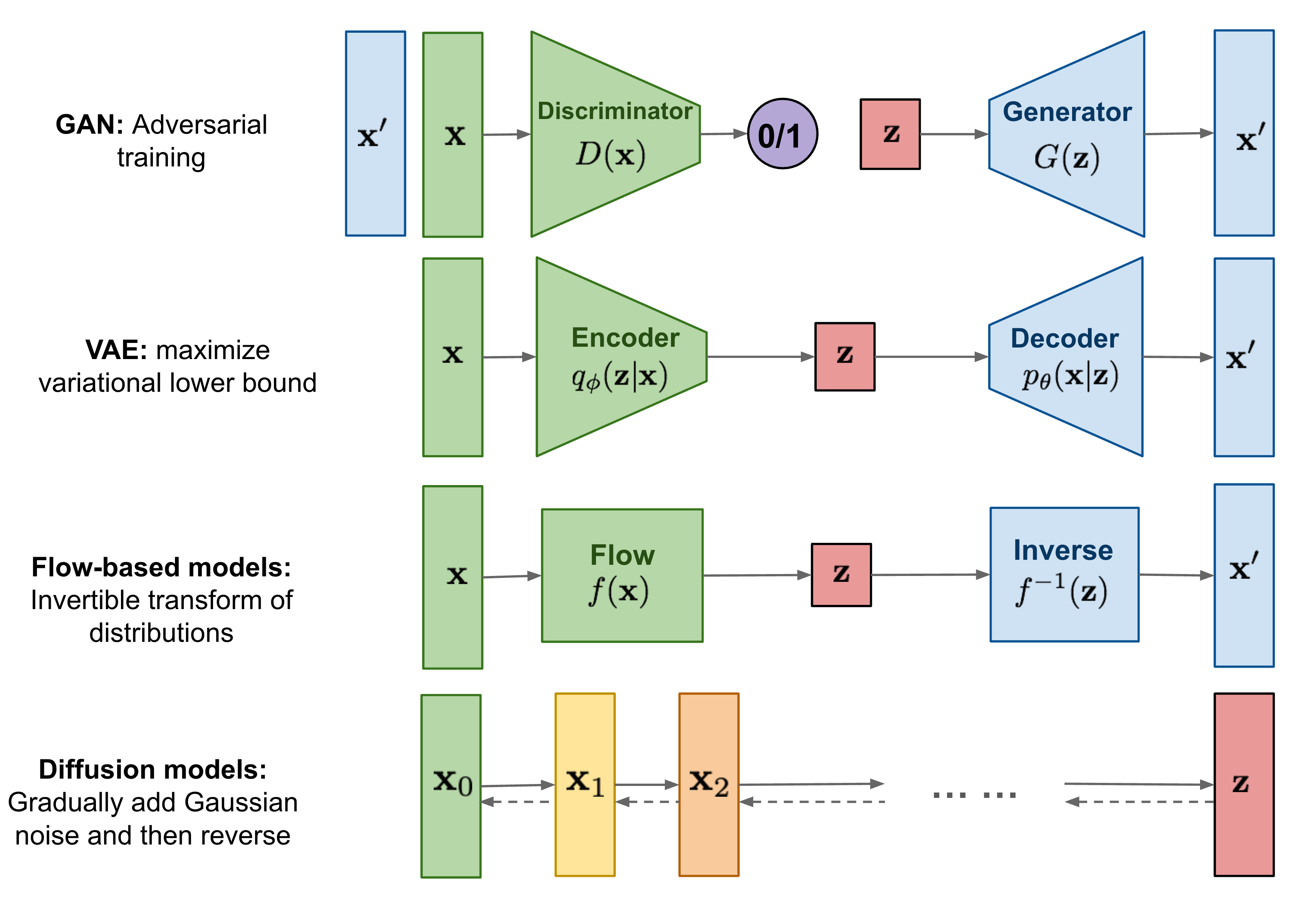
하지만 diffusion model을 text data에 적용하기 위한 시도는 있어왔는데 그 중 대표적인 것이 diffusion model을 이용하여 contollable text generation을 시도한 Diffusion-LM이다.
Controllable text generation이란, 사용자가 원하는 특정 attribute을 control하며 text를 생성해내는 것을 의미한다.
간단한 예로는 단순히 문장을 생성해내는 것이 아닌 긍정적인 내용의 문장을 생성해내거나, 특정 문장 구조에 부합하는 문장을 생성해내는 등의 task가 존재한다.
Diffusion-LM은 기본적인 diffusion model의 방식을 차용하되, discrete한 text를 continuous space에 mapping하기 위한 embeding 과정, 그리고 embedding한 vector를 다시 text로 바꾸기 위한 rounding 과정이 추가로 존재하고, controllable texte generation을 위해 특정 attribute와 관련된 external classifier의 도움을 받아 학습을 진행한다. 하지만, classifier가 attributes-oriented이고 모든 attributes에 대한 학습이 불가능하기 때문에, general한 conditional language modeling으로 일반화는 불가능하다. 특히나, condition 또한 sequence of words인 일반적인 sequence-to-sequence와 같은 경우에는, 수많은 condition(sequence of words)에 대해 학습을 진행하는 것이 불가능하기 때문에 Diffusion-LM을 적용하기란 매우 어렵다.
따라서 이 논문에서는 external classifier에 구애받지 않고, Seq2Seq text generation tasks를 수행할 수 있게 하는 DiffuSeq 모델을 제시하고자 한다.
하나의 단일 모델을 사용하여 context x가 주어진 target sentence w의 conditional probability $p(w|x)$를 모델링함으로써 Diffuion-LM처럼 external classifier에 의존하여 매번 다른 모델을 생성하는 것이 아닌, 하나의 complete model을 통해 data distribution을 fit하고 conditional guidance를 활용하는 것이 가능하다는 장점을 가진다.
아래 그림은 단순한 diffusion model, Diffusion-LM과 DiffuSeq를 비교한 그림이다.
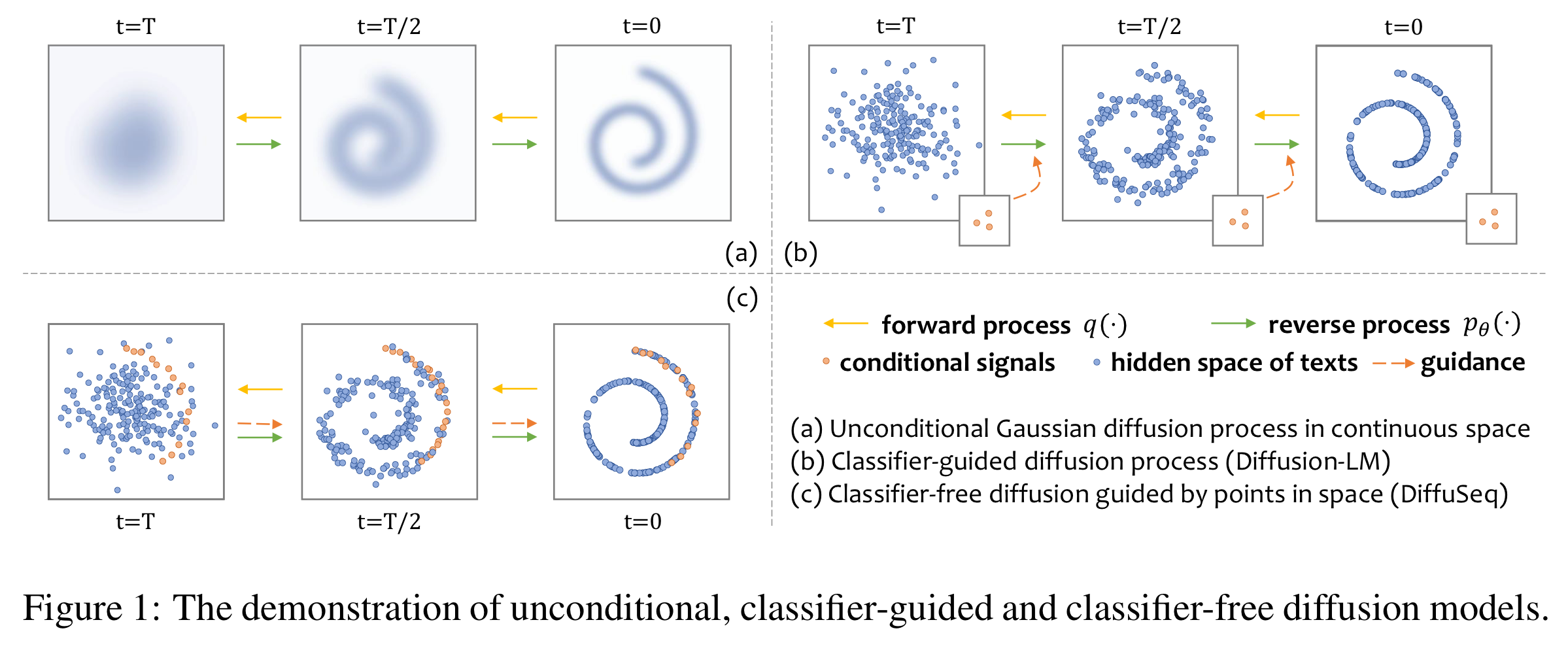
Preliminary and problem statement
Preliminary
Diffusion model은 데이터를 생성해낼 수 있는 특정한 패턴을 찾아 데이터를 생성해내는데, 패턴을 익히기 위해 두 가지 과정을 거친다.
- Forward process에서는 original data $x_0$에 diffusion step T에서는 $x_T$ ~ $N(0, I)$이 되게끔 계속해서 Gaussian noise를 더해줍니다. 이 때 각 step은 $q(x_t|x_{t-1}) = N(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I)$로 표현되고, $\beta_t \in (0, 1)$는 diffusion step t에서 얼만큼의 노이즈를 더해줄 것인지를 결정하는 hyperparameter이다. Forward process는 $\beta_t$가 hyperparameter이기 때문에 별도로 학습이 요구되는 parameter가 존재하지 않는다. 따라서 Forward process는 학습 과정에 포함되지 않는다.
- Reverse process에서는 diffusion model $f_\theta$를 학습하여 forward process를 통해 얻은 noise data $x_T$에서 점차 노이즈를 제거해가며 original data $x_0$를 reconstruct하고자 한다.
Problem Statement
Diffusion model을 text data에 적용하려했던 대부분의 선행연구들은 unconditional sequence modeling에 초점을 두고 있었다. DiffuSeq는 sequence-to-sequence text generation을 목표로 하고, 특히 source sequence $w_x$가 주어지면 $w_x$를 조건으로 하는 target sequence $w_y$를 생성할 수 있는 diffusion model을 학습하는 것을 목표로 한다.
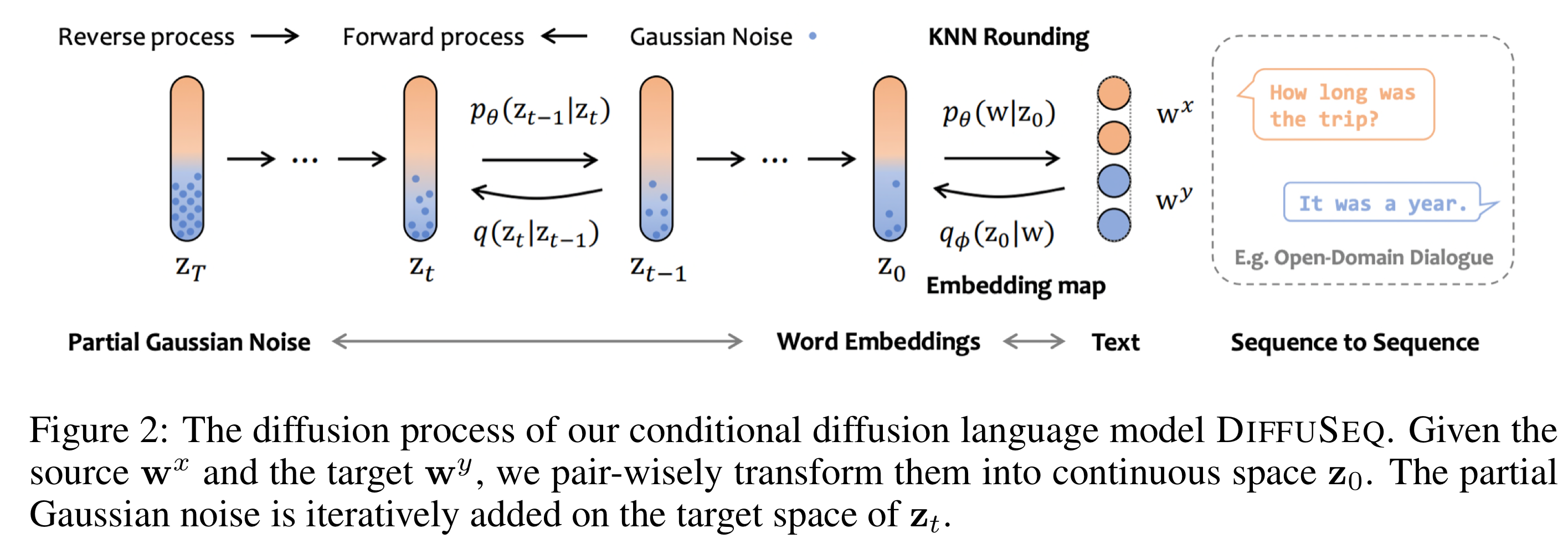
DiffuSeq
Forward Process
우선, Diffusion-LM과 동일하게 embedding 과정을 거친다. 하지만 Diffusion-LM이 Emb(w)를 통해 단순히 text(w)를 continuous space에 embedding했다면, DiffuSeq에서는 source sequence $w^x$와 $w^y$를 concat하여 embedding해 continous space $z_0$에 매핑해준다.

그에 따라 DiffuSeq의 embedding은 다음과 같이 표현된다.
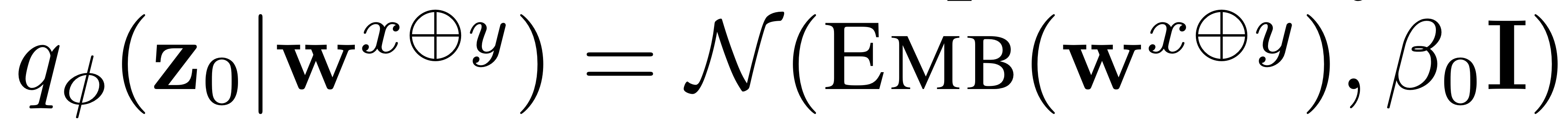
그 이후, 매 forward step $q(z_t|z_{t-1})$마다 이전의 hidden state $z_{t-1}$에 noise를 더해 $z_{t}$를 얻는다.
$z_t$ 중에서 $w^x$에 해당하는 부분을 $x_t$, $w^y$에 해당하는 부분을 $y_t$로 표현한다.
그리고, $z_t$ 전체에 noise를 더하는 일반적인 diffusion model과는 다르게, DiffuSeq에서는 $y_t$에만 noise를 더한다. 이를 partially noising이라 부른다.
Reverse Process with Conditional Denoising
Reverse process의 목적은 $z_t$의 noise를 제거하여 original $z_0$을 recover하는 것이다. 이는 아래의 process를 통해 이루어진다.
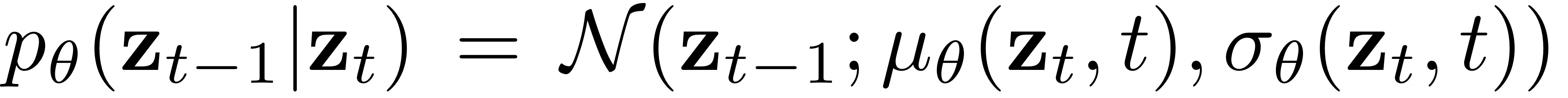
Oringinal diffusion process와 마찬가지로 variational lower bound를 다음과 같이 정의한다.
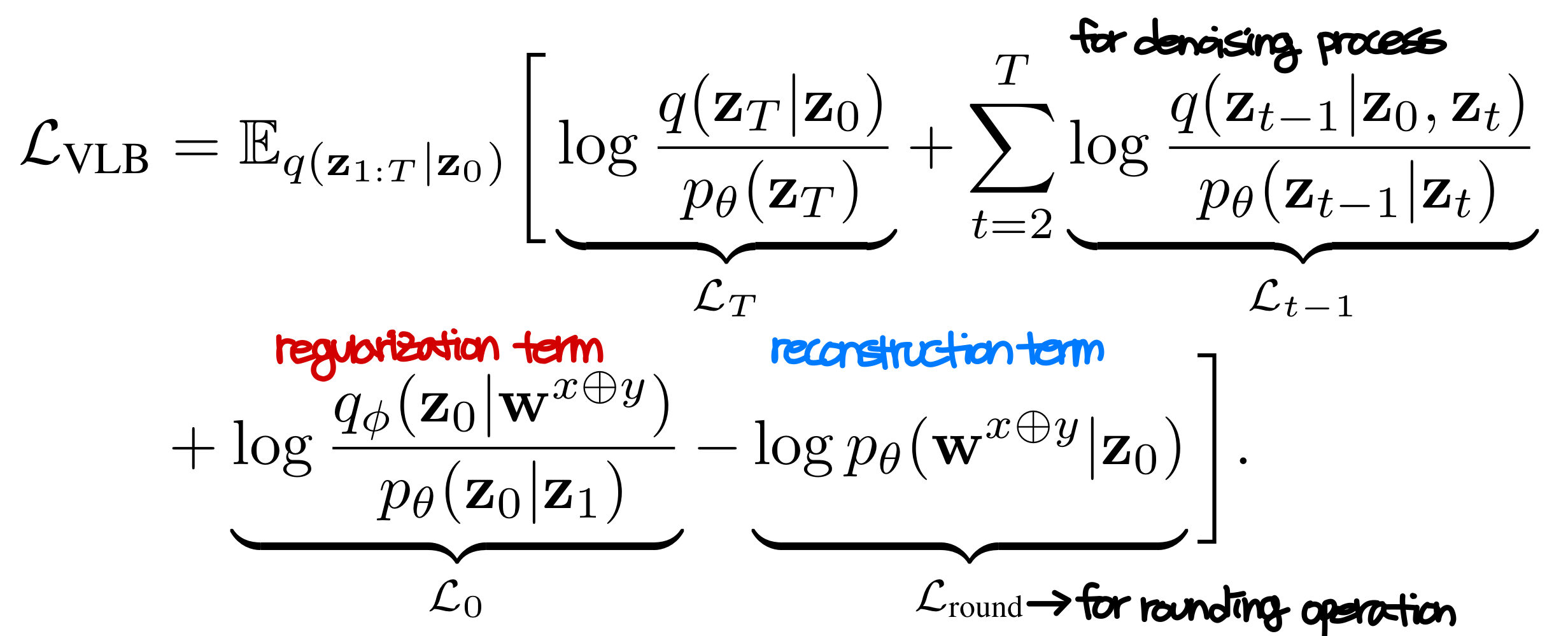
그리고 해당 수식은 다음과 같이 보다 간단한 형태로 표현이 가능하다고 한다.

model $f_\theta$로 transformer를 사용하기 때문에 자연스레 모델은 $x_t$와 $y_t$ 사이의 의미론적 구조를 익히게 된다.
또한, 같은 이유로, 위의 simplified training objective의 첫번째 term이 loss를 $y_0$에 관해서만 계산을 하고 있음에도, $y_0$ reconstruction에는 $x_0$ 고려가 되고, 따라서 이 첫번째 term의 gradient는 $y_0$을 학습하는 것 뿐만이 아니라 $x_0$를 학습하는데에도 영향을 미치게 된다.
Connections to AR, Iter-NAR, and Fully-NAR Models
DiffuSeq은 iterative non autoregressive model로 분류할 수 있다. DiffuSeq을 보다 이해하기 위해 autoregressive model, iterative non-autoregressive model, fully non-autoregressive model의 관계에 대해 살펴보자.
아래 그림은 AR모델, Iter-NAR모델, Fully-NAR 모델이 각각 학습을 어떻게 하는지 그림으로 표현한 것이다.
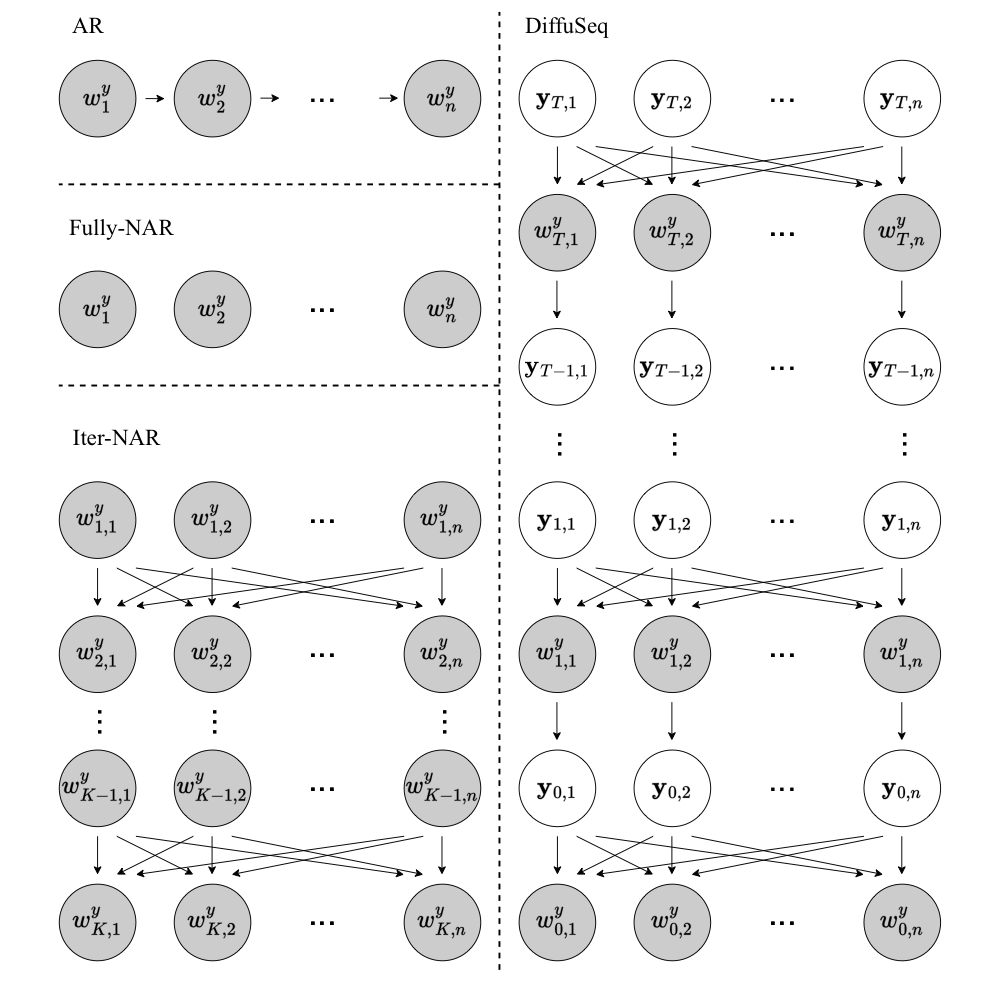
condition $w^x$가 주어졌을 때의 $w^y$에 대한 conditional probabiltity $p(w^{y}_{1:n}|w^x)$을 학습하는 Conditional Sequence Generation를 살펴보자.
우선 AR모델은 left-context에 기반하여 이를 학습해간다.

반면에 fully-NAR model은 매 time step마다 독립적으로 conditional probability에 대해 학습해간다.
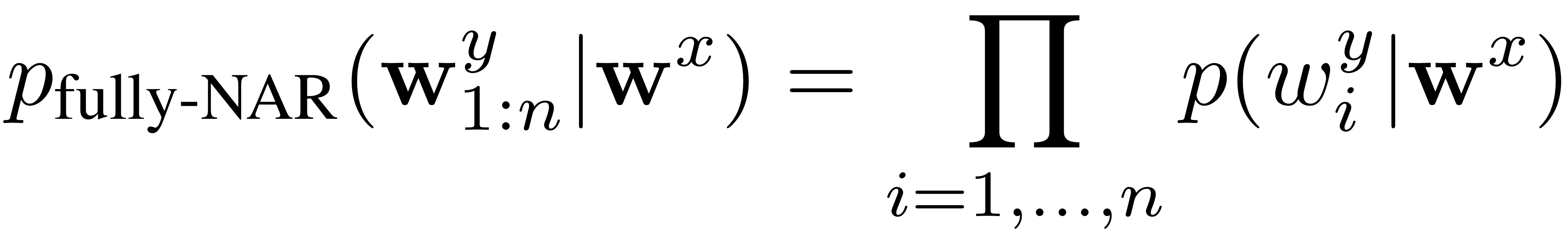
선행 연구들에 따르면, AR모델과 fully-NAR모델 사이에는 conditional total correlation이라고 부르는 gap이 존재한다고 한다. 이 gap이 NAR모델을 이용하였을 때 AR모델보다 성능이 급격하게 저하되는 주요 원인이었다고 한다.
Iterative-NAR 모델은 $w^{y}_{1:K-1}, w^{y}_{K} = w^y$라는 intermediate sequences를 도입해서 이 gap을 없앨 수 있었다고 한다.

DiffuSeq을 iterative-NAR의 형태로 표현하면 아래와 같이 표현할 수 있다.
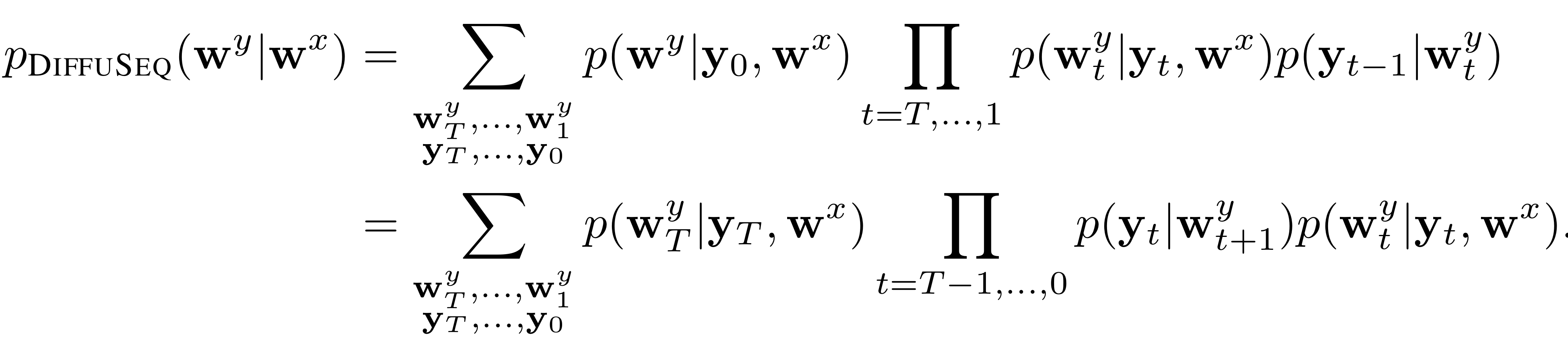
Training and Inference Methods
NLP dataset의 높은 차원과, 긴 diffusion step이 비효율적 학습의 원인이 되기도 한다고 한다. 따라서 importance sampling을 적용하여 이 문제를 해결하였다고 한다. Importance Sampling에 대한 보다 자세한 설명을 아래 참조한 유튜브 링크를 보면 좋을 것 같다.
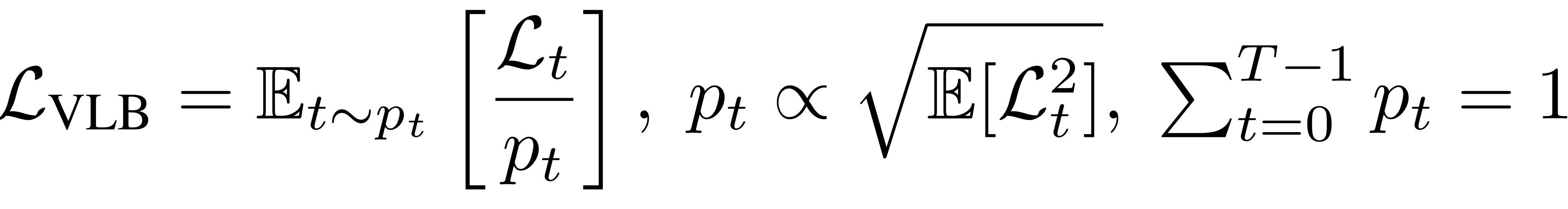
추가로 generation의 quality를 높이기 위해 Minimum Bayes Risk decoding strategy도 적용한다.
Minimum Bayes Risk decoding이란, 단순한 언어 생성모델처럼 가능성이 가장 높은 하나의 단어만을 output으로 출력하는 것이 아니라, 가능한 모든 단어 후보군에 대하여 특정 loss function(논문에서는 negative BLEU score를 사용)에 대해 가장 적은 loss를 갖는 단어를 최종 output으로 결정하는 방법이다.
Experiments
DiffuSeq을 4개의 task에, 6개의 AR/NAR baseline model과 비교하면서 실험을 진행하였다.
Experimental Setup
| Task | Dataset |
| Open domain dialogue : Generate informative responses given a dialogue context |
Commonsense Conversation Dataset * Reddit single-round dialogs * Over 3 million conversational pairs |
| Question Generation : Generate questions given a context as input |
Quasar-T * generated 119K training samples in addition using the dataset |
| Text Simplification : revise the complex text into sequences with simplified grammar and word choice |
Dataset constructed by Jiang et al. (2020) :Neural CRF Model for Sentence Alignment in Text Simplification |
| Paraphrase : generates an alternative surface form in the same language expressing the same semantic content |
Quora Question Pairs * sourced from community question answering from Quora with 147K positive pairs |
Baselines
- AR Model - Normal encoder-decoder architecture
- GRU with attention
- Transformer
- AR Model - Finetuned large pre-trained language model
- GPT2
- GPVAE
- Iterative NAR Model
- LevT
Evaluation
- Quality(higher the better)
- BLEU
- ROGUE
- BERTScore: string-similarity-based metrics(BLEU, ROGUE)가 open-ended-generation에서는 최적의 평가방법이 아닐 수 있기 때문에 generated sentence와 reference사이의 semantic similarity를 측정하기 위해 사용
- Diversity
- distinct unigram: generated sentence 내부의 다양성을 측정하기 위해 사용
- sentence-level self-BLEU: 하나의 source sentence로 부터 나온 output들 사이의 n-gram overlap을 측정하기 위함(lower the better)
- diverse 4-gram: 하나의 source sentence의 output들 중 고유한 4-grams의 비율을 측정하기 위해 사용(higher the better)

Quality면에서 DiffuSeq은 baseline들과 성능이 유사하거나 오히려 앞서는 모습도 보이고 있다. 동시에, 동일한 input sentence에 대해서는 DiffuSeq 다른 모델들보다 diverse output을 생성하는데에 있어서는 우수한 성능을 보이고 있다.
DiffuSeq은 기존 baseline model들에 비해 quality를 잃지 않으면서도 더욱 diverse한 sentence를 생성해낼 수 있다는 데에서 크게 의의가 있다.
'ML \ DL > Paper Reviews' 카테고리의 다른 글
| Attention is all you need (0) | 2023.03.24 |
|---|---|
| Efficient Estimation of Word Representations in Vector Space (0) | 2023.03.09 |
| Attention Is All You Need (0) | 2022.12.01 |
| Long Short-Term Memory (0) | 2022.11.11 |
| Latent Dirichlet Allocation (0) | 2022.11.03 |